-
[Keras] Sequential Model (순차모델) 사용 예제 - 단일 layerDeep Learning 공부자료/DL\ML\AI 구현 및 실습 2020. 5. 26. 23:32
Keras 에서는 신경망 모델을 만드는 방식 중 하나인 Seqential Model을 제공한다.
이는 순차적으로 layer를 더해나가는 방식으로, 매우 간단하다.
Training Set & Test Set 생성하기
우선, 모델을 통해서 학습할 데이터와, 학습된 모델을 테스트할 데이터를 생성하자.
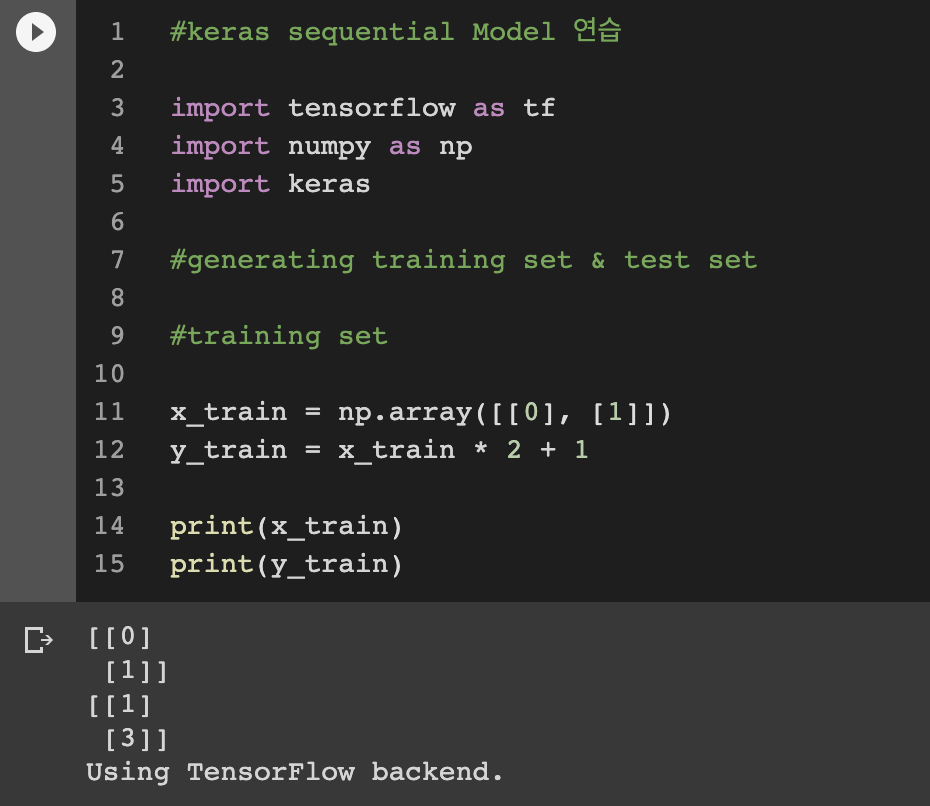
input과 output의 shpae과 dimension을 찍어보면 아래와 같다.
x_train은 2행 1열의 2차원짜리 행렬임을 확인했다.

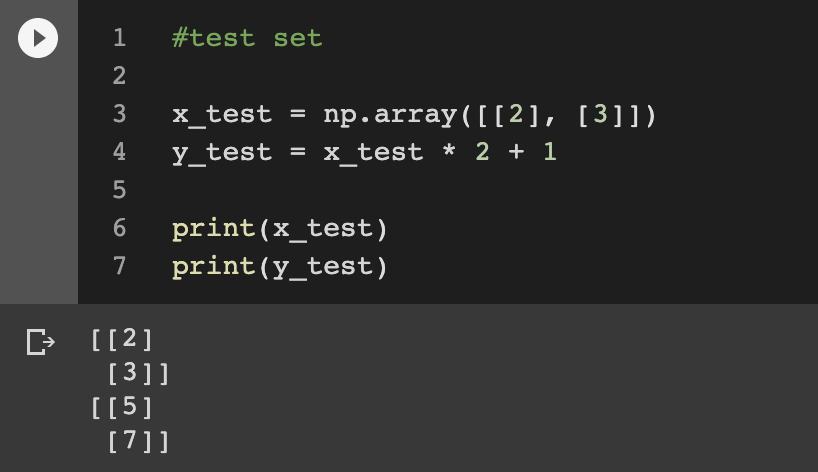
위의 training set과 같은 방식으로 test set도 생성한다.
Keras의 Sequential Model 생성하기
Sequential Model 생성하기
아래처럼 model을 생성하고, 그 모델의 type을 찍어보면,
keras 자체 엔진에서 제공하는 sequential class를 통해 생성되었음을 확인할 수 있다.

Model의 Node 구성하기
add 함수를 사용해서 model에 node를 추가할 수 있다.
해당 함수를 사용하면 이미 model 내부에 있는 node들과 현재 추가하는 노드를 연결시킬 수도 있다.
해당 예제에서는 input과 output이 각각 한 개인 node를 만들었고,
summary 함수를 사용해서 model의 형태를 찍어볼 수 있다.
이때 input_shape = (1, ) 대신에 input_dim = 1 로 정의해도 괜찮다.
shpae을 쓰면, 행의 개수를 의미하고 dim을 쓰면 input의 차원을 이야기 해주는 것이다.
Dense 함수는 input과 output을 모두 연결해주는 NN layer이다. keras는 Dense를 class로 구현하였으며
Dense로 만들어준 node는 weight와 bias 변수를 각각 갖게 된다.

Model 학습 시키기
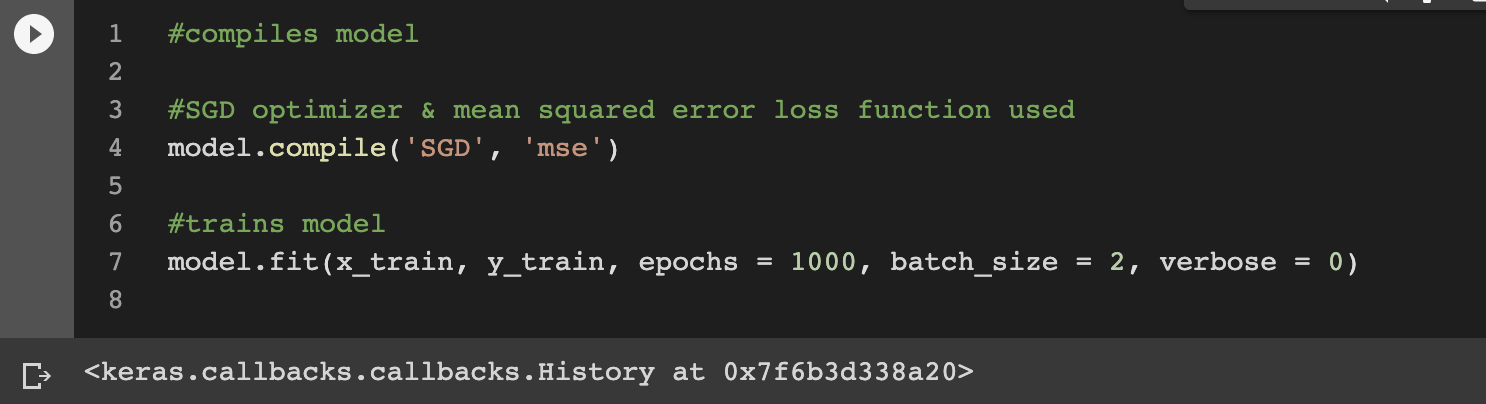
모델을 학습 시키기 전에 compile 함수를 사용하여, 학습 과정에 필요한 여러 설정들을 해준다.
loss function과 optimization 기법 등을 정의해줄 수 있다.
compile 함수는 인자를 총 세가지 받을 수 있는데,
첫번째 인자는 optimizer로 학습 과정에서의 최적화 방식을 설정해준다. 'adam' 이나 'sgd' 처럼 문자열로 선언할 수도 있다.
두번째 인자는 loss로 loss function을 설정하는 인자이다. regression의 경우 mean_squared_error(평균 제곱 오차)를 사용할 수 있고,
multi class classification의 경우 categorical_crossentropy (범주형 교차 엔트로피) 등을 사용할 수 있다. keras는 다양한 loss function을 지원하는데, 이에 관해서는 keras tutorial 홈페이지를 참고하면 좋겠다.
세번째 인자는 metircs로 학습을 모니터링하기 위한 지표라 생각하면 되고, 딱히,, 뭔가 설정할 필요가 없다면 그냥 default로 두자.
모델을 학습 시키는 함수는 fit 함수 이다.
모델이 각종 parameter를 update 시키는 과정을 training 하는 과정을 fitting이라고도 해서, 함수의 이름이 이렇게 붙여진 듯 하다.
fit 함수는 기본적으로는 인자를 총 네가지 받는다.
첫번째 인자는 training data set이고, 두번째 인자는 training 과정에서 labeling 된 데이터로
각각 x_train, y_train 이라고 생각하면 된다.
세번째 인자는 epoch로 학습의 횟수를 의미한다.
네번째 인자는 batch_size로 기본 값은 32라고 하는데, mini batch gradient descent로 설정 되어 있는 것이다.
mini batch gradient descent를 사용하고 싶지 않다면 None으로 설정 해준다.
(세번째 이후부터는 순서를 지킬 필요는 없고, 인자명을 명시해줘야한다.)
그 외에는 verbose나 validation_data, validation_split 등의 인자가 있는데,
validation_data는 검증 데이터를 사용할 경우에 쓰고, valiation_split은 validation_data 대신에 사용할 수 있는 것이다.
validation_split의 경우 별도의 검증 데이터를 주는 것이 아니라 학습 데이터의 일부를 검증 데이터로 빼내서 쓰는 것이다.
verbose는 학습 중에 출력할 문구를 선정하는 것으로 0이 기본으로, 아무것도 출력하지 않는 것이고
1은 훈련의 진행도를 의미하는 막대를 보여주고, 2는 미니 배치마다 loss 정보를 출력한다.
Model 평가하기
케라스 라이브러리에는 모델의 정확도를 평가하는 evaluate 함수가 있다.
세가지 인자를 받는데 각각 x_test, y_test, batch_size이다.
지금 예제의 경우는 뉴런 하나짜리 모델이라 당연히 정확도가 구릴수 밖에 없다.

Model 예측하기
케라스 라이브러리는 어떤 입력에 대한 모델의 출력값을 확인 해 주는 predict 함수를 제공한다.
두 개의 인자를 받는데 각각 예측하고자 하는 데이터와 batch_size 이다.
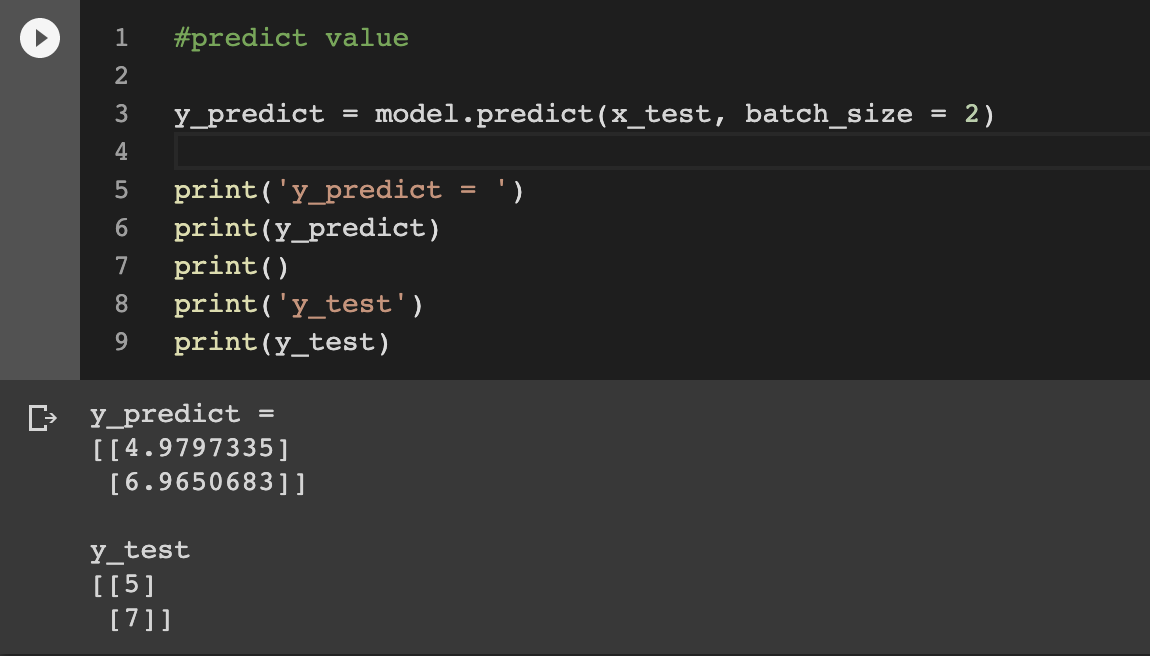
좀 더 정확한 예측을 위하여 더 깊은 네트워크를 지닌 모델을 만들어보자!
'Deep Learning 공부자료 > DL\ML\AI 구현 및 실습' 카테고리의 다른 글
[Keras] Sequential Model (순차모델) 사용 예제 - multi layer (0) 2020.05.26 [TensorFlow] 텐서플로우 2.0 예제 01 (Colab 환경) (2) 2020.05.26 [Keras] 처음 접해보는 Keras (0) 2020.05.26 [Colab] 사용법 - Github 코드 활용하기 (0) 2020.05.24 [Colab] 사용법 - 구글 드라이브 연동하기 (0) 2020.05.24