-
[논문리뷰] Accurate Image Super-Resolution Using Very Deep Convolutional Networks (VDSR)Paper Review/Computer Vision 2020. 3. 26. 19:39
해당 논문은 이전에 소개한 SRCNN의 문제점을 세 가지 측면에서 분석하고, 보다 더 깊은 deep convolutional network를 모델에 사용하여 문제점을 해결한 VDSR 모델을 소개합니다.
Abstract
VDSR은 VGG-net 에서 영감을 받았고, 네트워크의 깊이에 따라서 정확도가 올라간다는 아이디어를 바탕으로 했습니다. Input과 ground truth의 차이가 존재하는 부분인 residual을 학습 시키고, 높은 learning rate를 사용한다는 점이 SRCNN과의 차이입니다.
VGG-net이란?
더보기VGG-net 모델을 기점으로 네트워크가 깊어졌습니다.
VGG-net의 목표는 깊이와 성능 사이의 관계 분석이었는데, 3X3 filter로 세 차례 convolution한 것이 7X7 filter로 한 번 convolution한 것에 비해서 좋은 성능을 내는지를 파악하고자 했습니다.
3X3으로 세 차례 convolution하면, 7X7을 사용할 때에 비해서
1) 학습할 parameter 수가 적어집니다 -> 트레이닝 속도가 빨라집니다.
2) 네트워크가 깊어질 수록 non-linearity가 증가합니다.
Introduciton
VDSR 모델은 very deep convolution network를 사용한 모델이니만큼, 당연히 SRCNN에서 많은 영향을 받았습니다.
최초로 SISR 문제에 deep CNN을 적용한 모델인 SRCNN은 이전에 비해 간단한 모델로 상당한 효과를 냈지만, 다음과 같이 세 가지 측면에서 한계가 있었습니다.
1) Conetext : small image region의 contextual 정보에만 의존했는데, 이는 Layer의 수가 3개라 생긴 문제입니다.
2) Convergence : training convergence의 속도가 매우 느립니다.
3) Scale Factor : 하나의 모델은 single scale에 대해서만 적용이 가능해서, 새로운 scale이 요구되는 경우, 모델을 새로 학습해야합니다.
이런 한계점을 VDSR은 다음과같이 해결합니다.
1) Context : larger respective field를 적용합니다. (기존 SRCNN의 13X13 대신 41X41 적용) 이는 3X3 layer 20개를 사용함으로써 가능해졌습니다.
2) Convergence : residual-learning과 high learning rate를 적용합니다.
3) Scale Fator : multi-scale을 다루기 위한 single network를 따로 설계하고 학습합니다.
Contribution
Very deep network를 사용하면, 정확도는 좋아지지만 학습 속도가 너무 느린 문제가 있습니다. 이를 해결하기 위해서 high learning rate를 사용하는데, 학습률이 커지면 gradient가 과도하게 커지는 문제가 생깁니다. 따라서 VSDR은 high learning rate 뿐 아니라 residual learning과 gradient clipping을 같이 적용하여 모델을 설계 합니다.
Related Work
더보기1. Convolutional Network for Image Super-Resolution
Model
SRCNN은 3개의 layer를 사용하는데, 해당 논문은 layer가 깊어질 수록 네트워크의 성능이 향상됨을 주장하며 VDSR에 20개의 layer를 사용합니다.
Training
SRCNN은 직접 바로 HR image를 예측해 내는 모델입니다.
실제로 Input image와 Output image는 상당부분 비슷한 점이 많습니다. 이런 특성을 이용하여 VDSR은 input과 ground truth 사이에 차이가 발생하는 residual image를 학습하여 더 빠른 학습 속도로 더 정확한 HR image를 예측을 할 수 있습니다.
Scale
multiple scale SR을 하기 위해서 각 scale 종류마다 model을 새로 학습 하는 방법도 있지만, 이건 너무 실용성이 떨어집니다. 따라서 VDSR은 multiple scale SR을 해결하기 위한 하나의 network를 따로 설계해서 학습합니다.
Proposed Method
1. Proposed Network
VDSR은 input으로 interpolated된 LR image를 받습니다.
정확도가 높은 output을 얻기 위해서 해당 모델은 very deep network를 사용하는데, 이 때 feature map의 크기가 계속 해서 줄어듭니다.
Surround pixel들은 보통 경계를 나타내기 때문에 center pixel을 추론하는데에 도움을 줍니다. 그런데 feature map의 크기가 줄어들면, surrond pixel의 정보를 활용하기 어려워지는 문제가 생깁니다.
이런 문제를 해결하기 위해서 VDSR에서는 conv layer에 들어가기 전에 image를 zero-padding (아래 이미지에서 각 layer 이전에 있는 Line) 시켜서 feature map의 크기를 input의 크기와 동일하게 유지시키고, surround pixel 정보도 잘 살려서, 이미지의 가장자리에 있는 pixel 예측도 잘 이뤄집니다.
SRCNN은 layer를 통과해서 나온 feature map의 크기가 각기 달라서, 효과적인 학습 수렴을 위해서는 layer마다 learning rate가 다 달라야 했습니다.
VDSR은 zero-padding을 통해서 feature map의 크기가 항상 같기 때문에, 모든 layer가 하나의 learning rate를 사용해도 충분하며, 이로 인해 학습시켜야 할 parameter 수가 줄어들어 학습 속도가 빨라집니다.
2. Training
input x : interpolated LR image
ground truth y : HR image
y hat = f(x) 이며 네트워크의 목표는 당연히 y에 유사한 y hat을 mapping 시키는 f를 학습시키는 것 입니다.
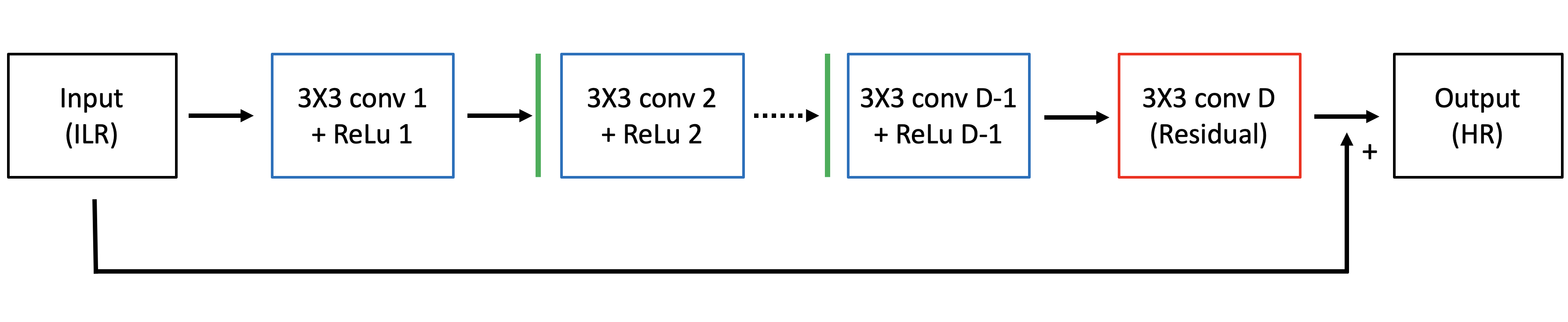
Residual Learning
SRCNN은 long-term memory를 유지해야 하는데, 이는 exploding/vanishing gradient 문제를 야기시킵니다.
이를 해결하기 위해서 VDSR에서는 Residual-Learning을 사용합니다.

SR 문제의 특성상, input과 output이 상당히 유사한데,
오른쪽 나비의 날개에서 노랑색 부분은 LR과 HR에서 거의 차이가 없어서, 차이를 계산하면 0에 근사한 값이 나옵니다. 나비 날개의 검정색 태두리 부분과 같은 경계 부근에서는 차이가 크게 나옵니다.
따라서 차이가 크게 나타는 부분에 대해서만 CNN을 통해 학습을 잘 시키면, 모델 전체가 더 빠르게 더 정확하게 학습될 것이란 아이디어를 바탕으로, 위의 다이어그램에서처럼 네트워크의 맨 마지막에 residual 을 추가합니다.
r = y - x로 정의하고, loss function은 \(1/2||r - f(x)||^2\) 로 정의 합니다.
High Learning Rate for Very Deep Network
트레이닝의 속도를 빠르게 하기 위해서 자주 사용되는 대처 중 하나가 learning rate를 높이는 것입니다.
해당 모델에서도 같은 기법을 사용하는데, 학습률을 높일 시 gradient가 폭발하거나 너무 작아져서 제대로된 학습을 하기 어려워지는 문제가 생깁니다. 이를 해결하기 위해서 adjustable gradient clipping을 사용합니다.
Adjustable Gradient Clipping
Gradient Clipping은 gradient의 범위를 [-Θ, Θ]로 한정하여 학습하는 것을 의미합니다.
Θ 값을 작게 두어서 gradient exploding 문제를 방지할 수 있습니다.
해당 논문에서는 Adjustable Gradient Cliiping이라는 기법을 제시하는데, gradient clipping에서 정한 gradient 범위를 learning rate에 반비례도록, [-Θ/γ, Θ/γ] 범위로 설정하는 것 입니다.
이렇게 하면, 학습 수렴의 속도를 극대활 할 수 있고, SRCNN이 학습 시키기 위해서 며칠이 걸린 작업을 VDSR로는 4시간 학습시킬 수 있었습니다.
Understanding Properties
VDSR 모델의 특성을 context, convergence, multi-scale 측면에서 알아봅시다.
1. The Deeper, the Better
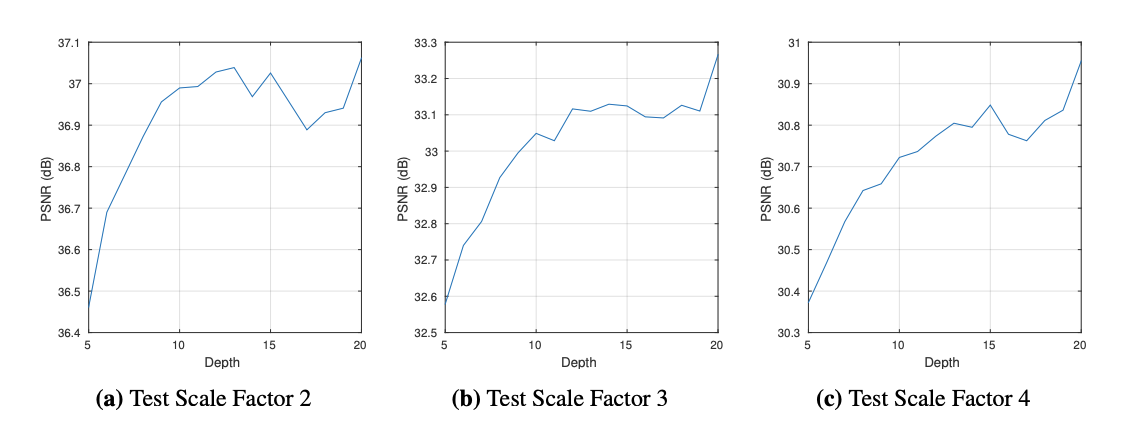
VDSR은 모든 layer에 3X3 filter를 적용하였고,
네트워크 깊이 D가 커질수록 receptive field size도 (2D + 1) X (2D + 1)로 커집니다.
Receptive field size가 커지면, 이미지의 디테일을 추론하늗네에 더 많은 contextual 정보를 사용할 수 있고, 이를 통해 더 많은 pixel을 분석할 수록, SR의 문제를 해결하기 위한 더 많은 단서를 얻을 수 있습니다.
위의 그래프는 Scale Factor을 바꿔가며, 네트워크의 깊이를 5에서 20으로 키우면서 실험한 결과입니다.
그래프를 통해서 알 수 있는 점은, 대부분의 경우 네트워크의 깊이가 깊어짐에 따라서 PSNR이 커지므로 성능이 좋아짐을 알 수 있습니다.
2. Residual-Learning
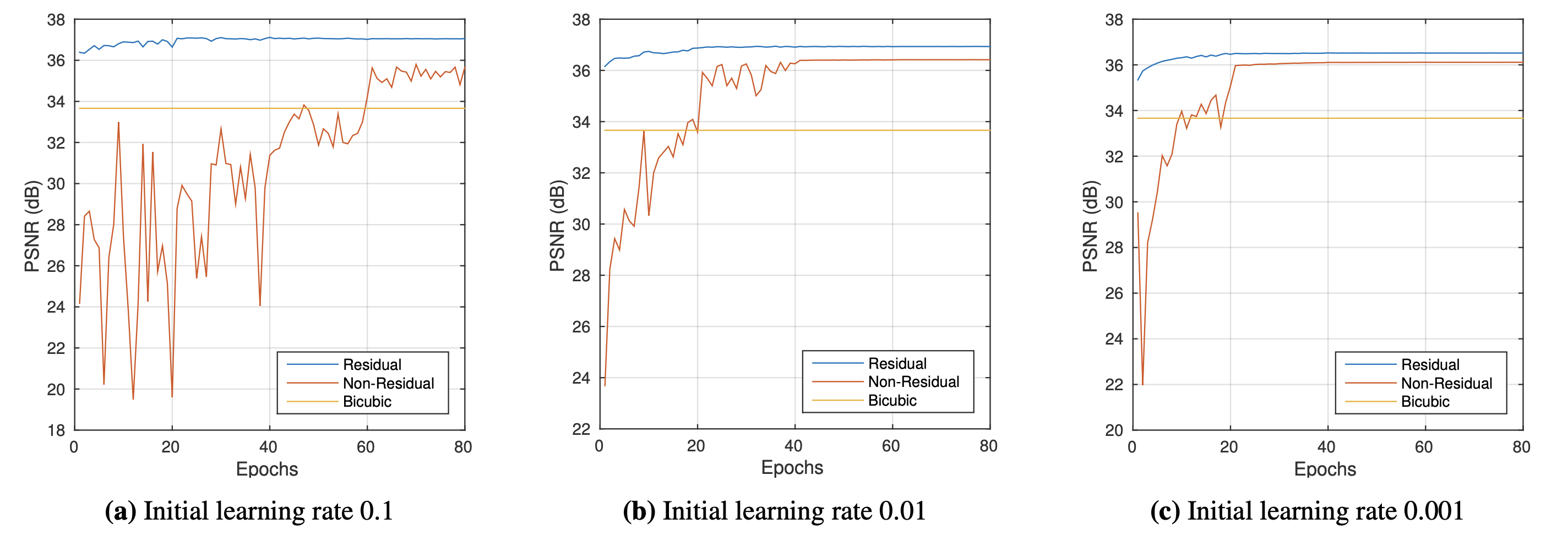
위의 그래프는 Residual Learning 적용한 경우와 적용하지 않은 경우의 학습 속도와 성능을 확인한 실험의 결과입니다.
Residual을 사용한 경우가 학습 속도가 훨씬 빠르고, PSNR 값도 더 높다는 것을 확인할 수 있습니다.
추가적인 흥미로운 점은, 작은 learning rate로는 큰 learning rate 사용시 나왔던 성능에 도달할 수 없다는 것입니다. 0.01 learning rate 사용 시에는 10 epochs 이후 36.9까지 PSNR이 나왔지만, 0.0001 learning rate을 사용하면 80 epochs가 지나도 PSNR이 36.52 밖에 안 나옵니다.
3. Single Model for Mutiple Scales

\(S_{train}\) : 학습에 사용된 single scale factor
\(S_{test}\) : \(S_{train}\) test에 사용된 single scale factor
위의 테이블을 통해서 우선 알 수 있는 점은, single-scale data에 대해서만 학습된 네트워크는 다른 scale 문제에 적용할 수 없다는 것이다.
\(S_{train}\) 을 2로 한 경우, scale factor 2에 대해서는 37.10으로 비교적 높은 PSNR을 기록하지만, scale factor 3과 4에서는 현저히 낮은 PSNR을 기록함을 알 수 있고, 이는 \(S_{train}\)을 3 과 4로 각각 학습한 경우에도 해당한다.
위의 테이블을 통해서 알 수있는 VDSR의 장점은, mutiple scale로 학습한 모델의 경우 각 scale의 PSNR이 각 scale에 대한 single-scale로 학습한 경우와 견줄만큼 잘 나온다는 것이다.
\(S_{train}\) = {2, 3, 4}로 학습한 경우 scale factor가 2인 경우 PSNR이 37.06이 나오는데, 이는 \(S_{train}\) = {2}로 학습한 경우의 PSNR 값 (37.10)과 매우 근사하다.
Self Q&A
더보기3.2절 Adjustable Gradient Clipping에서 'But as learning rate is annealed to get smaller, the effective gradient ( gradient multiplied by learning rate ) approaches zero and training can take exponentially many iterations to converge if learning rate is decreased geometrically.' 가 잘 이해가지 않습니다.
해당 논문에서는 zero-padding을 통해서 하나의 learning rate로 학습이 가능하다고 하는데, 3.2절의 설명에선 learning rater가 점점 줄어든다는 듯이 설명해서, 실제로 줄어들게 학습을 시키는건지 혹은 3.2절의 설명이 adjustable gradient clipping이 아니라 gradient clipping에 관한 설명인지 혹은 해당 모델에서는 learning rate가 변하지 않지만, 일반적인 adjustable gradient clipping의 개념은 learning rate가 줄어드는 경우도 handling하는 것이 목표인지 궁금합니다.
느낀점
더보기SRCNN에 이어서 두번째 읽은 CV 논문인데, 그래도 이제는 feature map이 뭘 의미하는지, 네트워크 구성은 어떻게 하겠다는 건지, 쟁점은 무엇인지 등 맥락은 좀 눈에 들어오는 것 같다.
SRCNN에 비해서는 실험의 결과들을 해석하는 것이 비교적 쉬웠고, CV에서 자주 사용되는 용어들이 아직은 좀 어색하지만, 그래도 몇 편 더 읽으면 익숙해지리라 기대해본다.
VDSR은 기존 모델들에서 크게 변화를 준 것 같진 않지만, residual을 사용한다는 점이 흥미로웠고, 속도 향상은 충분히 예견되지만 거기에 정확도도 향상된 다는 점이 놀라웠다.
Rule of Thumb 중 하나인 Gradient Clipping을 다뤄볼 수 있어서 재밌었다.
'Paper Review > Computer Vision' 카테고리의 다른 글