-
Lec03) Linear Regression의 cost 최소화 알고리즘의 원리 설명Deep Learning 공부자료/모두를 위한 딥러닝 2020. 3. 10. 01:15
Hypothesis and Cost
Hypothesis : \(H(x) = Wx + b\)
Cost Function : \(Cost(W,b)\) = \(1/m \sum_{i = 1}^{m} (H(x_i)-y)^2\)
linear regression의 목표 : cost를 minimize 시키는 W와 b 찾기
Simplified Hypothesis
계산의 편의를 위해서 b = 0으로 설정한다.
Hypothsis : \(H(x) = Wx\)
Cost Function : \(Cost(W,b)\) = \(1/m \sum_{i = 1}^{m} (Wx_i-y)^2\)
What \(Cost(W)\) looks like?
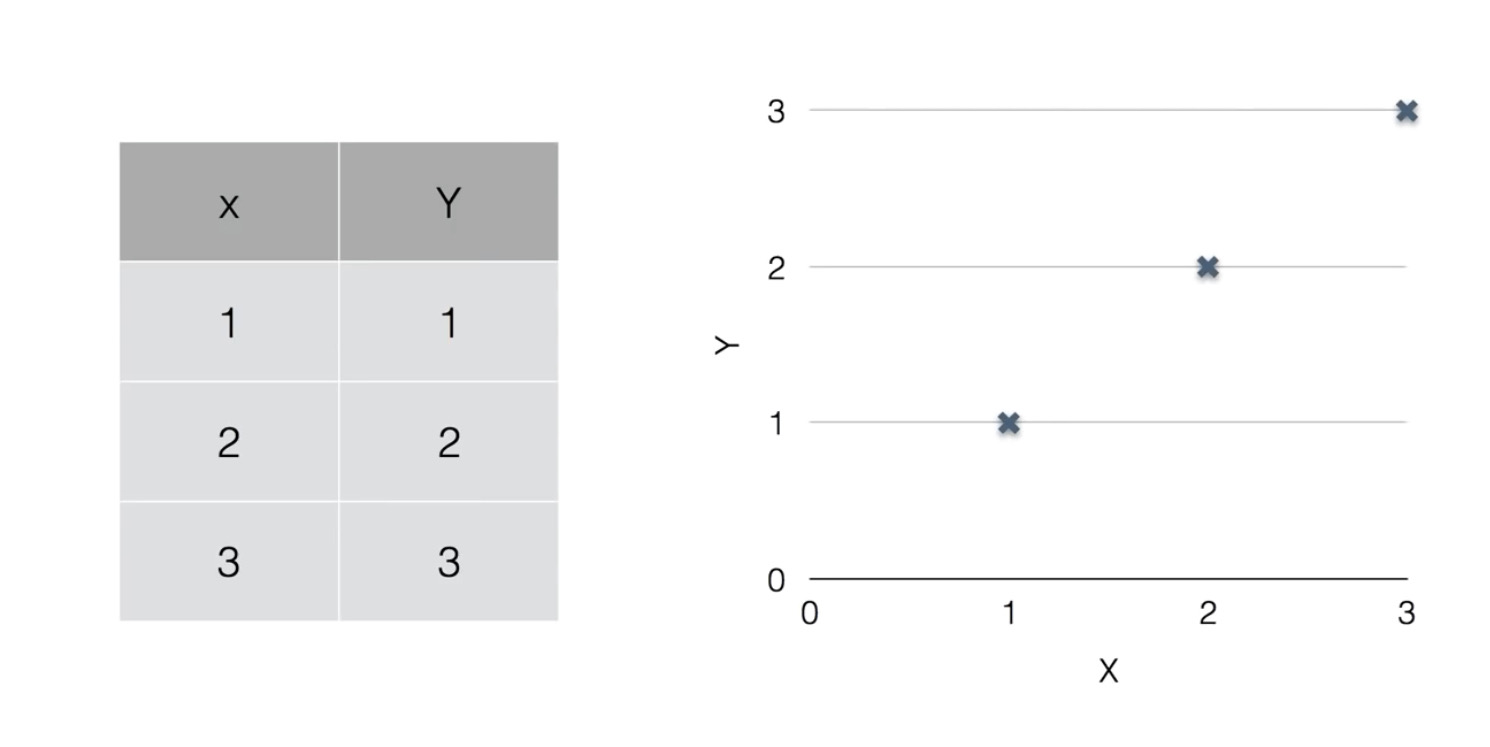
해당 예제의 cost function을 컴퓨터로 그려봤더니, 아래와 같은 그래프가 나왔다.

cost function의 값이 최소가 되는 점, 즉 W=1을 찾아 내는 것이 regression의 목적이다.
Gradient Descent Algorithm 적용 방식
안개 낀 산 꼭대기에서 하산 하기 위해서는 기울기가 완만한 쪽으로 이동해야 한다.
-
임의의 값에서 시작한다.
-
W와 b를 각 시행마다 조금씩 변경 하면서 를 줄여 나간다.
-
변경 시 가능한 최대로 를 작게 하는 W, b를 선정한다.
-
local minimum 을 찾을 때 까지, 1~3의 과정을 반복한다.
장점 : 어디에서 시작하던 minimum을 구할 수 있다.
단점 : 대표적인 local search algorithm. 대부분의 local search algorithm이 갖는 local minimum에 빠져서 global minumum을 찾지 못하는 한계를 갖고 있다. 하지만 random restart local research algorithm을 이용하여 해결할 수 있다.
Formal Definition
미분을 용이하게 하기 위해서 분모에 2를 곱함
$$Cost(W,b) = 1/2m \sum_{i=1}^m (Wx_i-y_i)^2$$
미분 과정은 아래와 같다.
$$W := W - α{\partial\over\partial W}Cost(W)$$ (α는 learning rate을 의미. 보편적으로 0.1을 사용)
$$W := W - α{\partial\over\partial W}{1/2m \sum_{i=1}^m (Wx_i-y_i)^2}$$
$$W := W - α{\partial\over\partial W}{1/2m \sum_{i=1}^m 2(Wx_i-y_i)x_i}$$
$$W := W - α{\partial\over\partial W}{1/m \sum_{i=1}^m (Wx_i-y_i)x_i}$$
$$W := W - α{\partial\over\partial W}{1/m \sum_{i=1}^m (Wx_i-y_i)x_i}$$ 가 Gradient Descent Algorithm의 수식이다.
이 수식을 여러번 실행 시키면서 minimize 시키는 W를 찾는다.
'Deep Learning 공부자료 > 모두를 위한 딥러닝' 카테고리의 다른 글
Lec02) Linear Regression의 가정과 cost function (0) 2020.03.10 Lec01) Machine Learning 용어와 개념 정리 (2) 2020.03.10 -